What does it take for your data agent to be trustworthy?

For any data agent to be successful, you need to have good user retention, and for that, it needs to be trustworthy. This is especially important for data agents because model, data, ETL and even docs update can regress agent quality. In this post, I explain why the common wisdom of writing more data docs and giving your agent more tools is ineffective at making your agent trustworthy, and what might actually be more effective.
Before we begin, let’s talk about what your internal data agent needs to do, to give a trustworthy answer. It needs to:
- reason about the intent of the user’s question,
- map that to the semantics (aka definitions) of your business, and
- map those to the structure of your data in the warehouse.
Intent — what does the user mean, e.g., when a user says ‘actives’ and ‘last quarter’, they mean ‘active users’ and ‘Nov–Jan’ because our fiscal year runs Feb to Jan.
Semantics — business definitions of important metrics and concepts. What is the definition of an “active user”, what’s the default lookback period, what are other ways of referring to the same term, etc.
Structure — grain of the data set, gotchas, common joins and filters, etc.
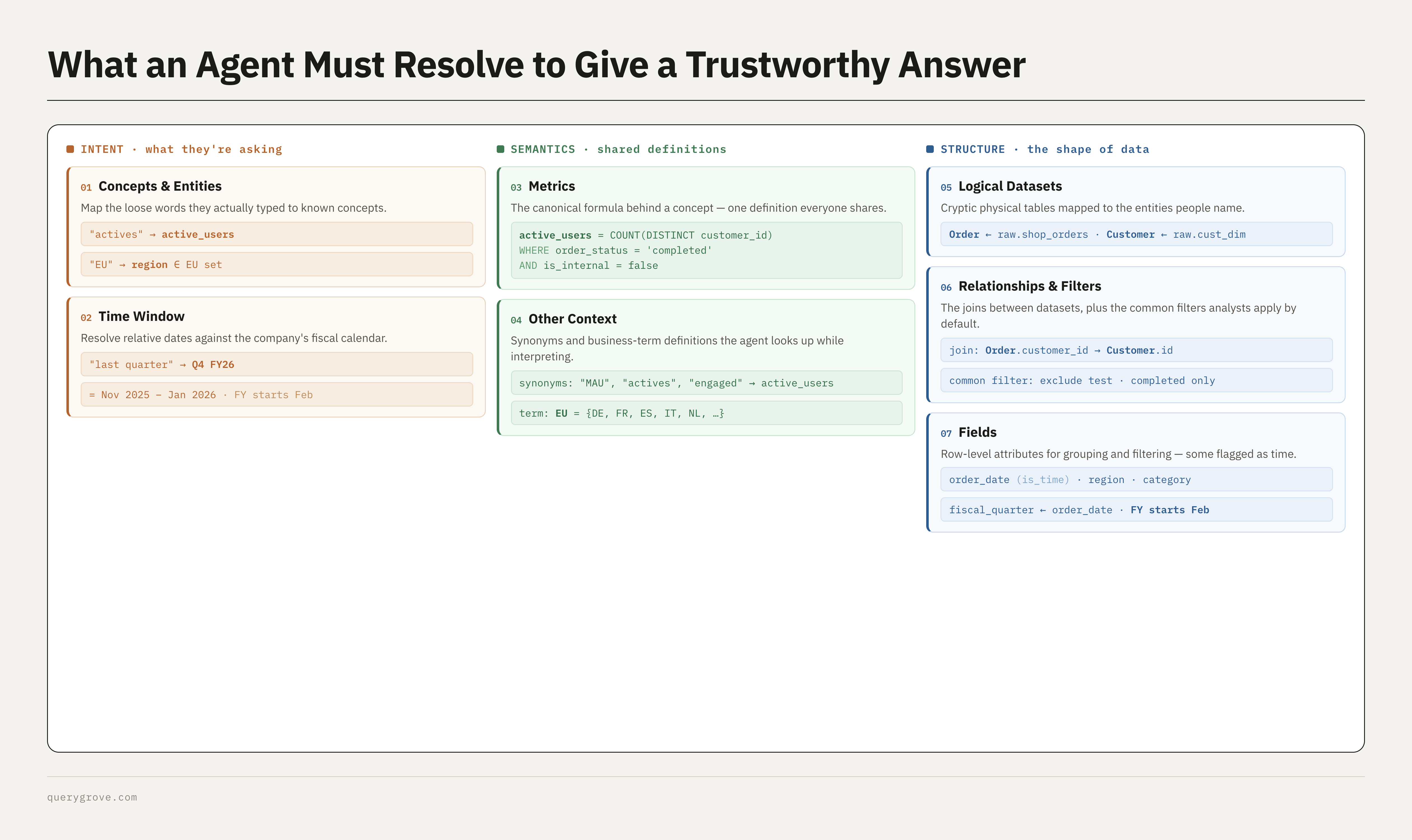
We don’t want the agent to make this stuff up so we need to provide this as context.
Writing more data docs or giving more tools is ineffective
Investing in more data docs or more tools for your data agent is misguided. Here goes the common wisdom:
- Write more data documentation — prompts, skills, knowledge base of .md files. You can even have various degrees of fanciness in generating these docs - like trickling down data descriptions based on lineage/common join patterns.
- Give your agent more tools for additional context — This may be a simple tool that is powered by a knowledge base of .md files or MCP server of your favorite data catalog.
But the above ways are NOT effective for two main reasons:
- Docs are not enforceable. They are merely guidance and we hope the agent’s instruction-following is good enough to follow those. Docs may contain conflicting information that the agent will resolve non-deterministically. I am pessimistic that these two problems (instruction-following and determinism) will get solved as models get better with transformer-based LLMs.
- Metadata powering the tools is not co-located with code. It is bound to drift. For all the talk about microservices over the last decade, LLMs have given us all a huge reason to do monorepos. LLMs can read, reason, update code and metadata at the same time in the same repo.
The more data you have, the worse the above problems get.
OK, so what do we do?
To make data agents trustworthy, we need to:
- Provide context about the semantics of the data, in addition to the structure.
- Enforce that the agent only answers questions from this context.
- Co-locate this context with ETL code, so there’s no drift.
Turns out such a thing already exists - it’s the semantic layer, which has several advantages:
- Semantics and data structure context - Provide context about the semantics (e.g., what does active user mean, what is the lookback period, etc.) and structure of data (which column to use for when user last logged in).
- Enforceable - You can enforce its usage by limiting your agent’s access to just the semantic layer, instead of the whole data warehouse.
- Governable and co-located - Govern it by checking it in the same code repo that houses your ETL code, so it remains in sync with your code.
The main challenge with using a semantic layer is that building it historically was a lot of work. That’s exactly where the key opportunity for AI is - reducing the barrier to creating and maintaining a high quality semantic layer. More on that another time.
Additionally, using a semantic layer that you own has the benefit of reducing dependence on data agent providers. You can switch from one model to another, one agent to another, much more easily - the same way you could switch from one warehouse to another, when using Iceberg.
Trust vs. Coverage
A key trade off organizations have to make is between trust and coverage. Since trustworthiness for agents is based on well-built semantic models, your initial coverage will be lower than letting your agent loose on your data warehouse.
Some caveats
- This post is only relevant for organizations of a certain scale. If you have 100 tables in your warehouse, your data agent’s context is small. You can do fairly well with giving your agent access to select gold tables, and writing your metric and concept definitions in a skill file checked into your ETL repo.